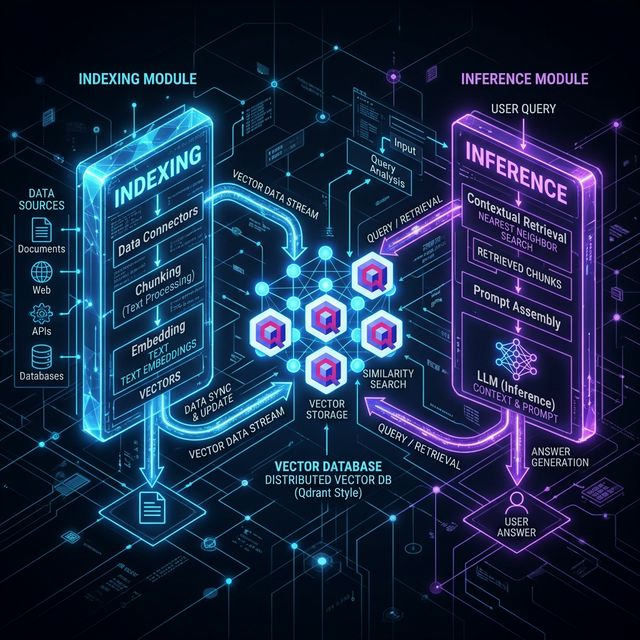
AI Architecture RAG Distributed System 💡 For AI engineers and CTOs evaluating whether to run LLMs locally — and why distributed architecture is the answer to VRAM bottlenecks. 🎯 Why Running LLMs Locally Is a VRAM …